SQL에서 계층 구조 데이터 표현 방식 비교
조직도, 카테고리, 댓글 등 우리가 개발하는 많은 기능에는 계층 구조가 포함됩니다. 관계형 데이터베이스는 본질적으로 평면적인 데이터를 다루기 때문에, 이러한 계층 구조를 효율적으로 저장하고 조회하는 것은 꽤나 까다로운 문제입니다.
이 글에서는 SQL 데이터베이스에서 계층 구조 데이터를 표현하는 대표적인 네 가지 방식인 인접 목록(Adjacency List), 중첩 집합(Nested Set), 폐쇄 테이블(Closure Table), 경로 열거(Path Enumeration) 모델을 비교하고 각각의 장단점을 정리합니다.
Adjacency List
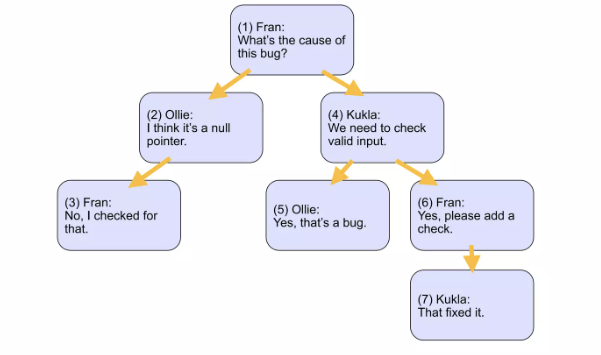
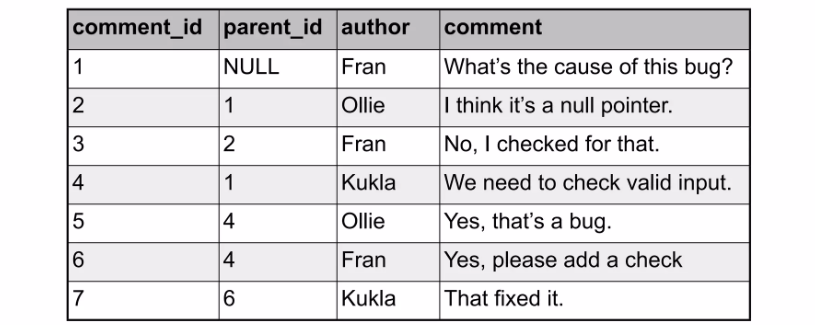
가장 직관적이고 널리 사용되는 방식입니다. 각 행(row)이 자신의 부모 행(parent)에 대한 참조(ID)를 갖는 구조입니다.
- 장점:
- 구조가 매우 단순하고 이해하기 쉽습니다.
- 새로운 노드를 추가하거나, 노드의 직속 부모를 변경하는 작업이 간단하고 빠릅니다.
- 단점:
- 특정 노드의 모든 하위 노드를 찾는 것(서브트리 조회)이 매우 비효율적입니다. 재귀 쿼리(Recursive CTE)를 사용해야 하며, 데이터베이스에 따라 성능이 저하될 수 있습니다.
- 계층의 깊이가 깊어질수록 쿼리가 복잡해지고 성능이 저하됩니다.
Path Enumeration
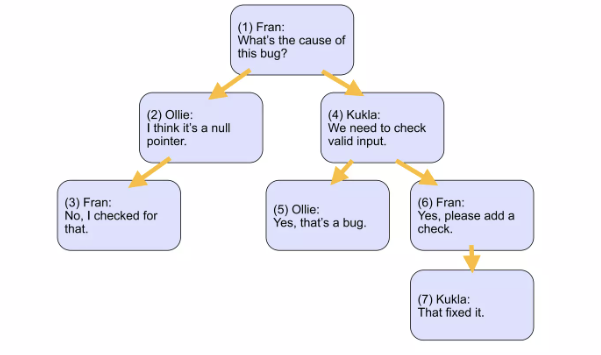
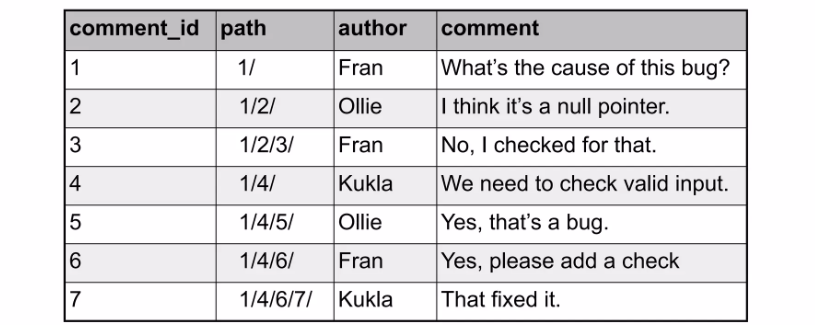
각 노드의 전체 경로를 문자열 형태로 저장하는 방식입니다. 예를 들어, Food > Fruits > Apple과 같은 형태입니다.
- 장점:
- 구조가 직관적이고 이해하기 쉽습니다.
- 특정 노드의 경로를 쉽게 파악할 수 있습니다.
- 단점:
- 문자열 기반이라 데이터베이스에 따라 인덱싱 및 검색 성능이 저하될 수 있습니다.
- 경로가 길어지면 저장 공간이 낭비될 수 있습니다.
- 부모 노드가 변경되면 모든 자식 노드의 경로를 업데이트해야 합니다.
Nested Set
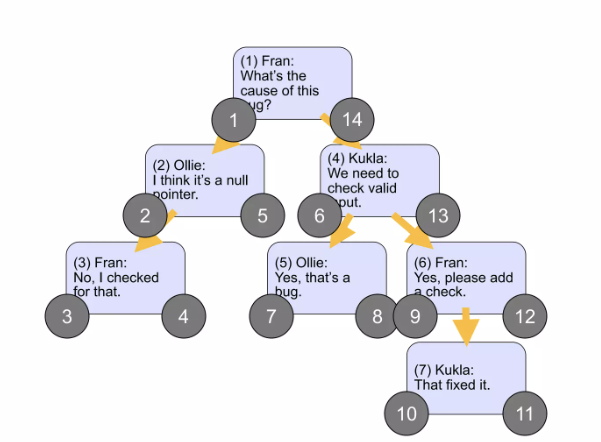
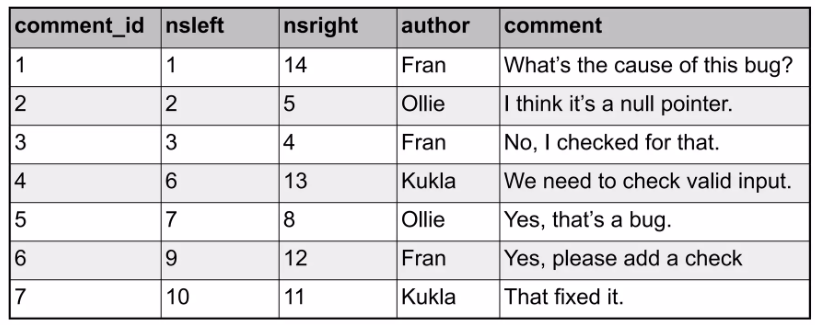
각 노드에 lft와 rgt라는 두 개의 숫자 값을 할당하여 계층을 표현합니다. 특정 노드의 모든 자손은 해당 노드의 lft와 rgt 값 사이에 포함됩니다.
- 장점:
- 서브트리를 조회하는 작업이 매우 빠르고 효율적입니다.
BETWEEN절을 사용한 간단한 쿼리로 가능합니다.
- 서브트리를 조회하는 작업이 매우 빠르고 효율적입니다.
- 단점:
- 노드를 추가, 수정, 삭제하는 비용이 매우 큽니다. 하나의 노드가 변경되면, 그 노드의 오른쪽에 있는 모든 노드의
lft,rgt값을 다시 계산해야 할 수 있습니다. - 구조가 비직관적이라 이해하고 구현하기 어렵습니다.
- 노드를 추가, 수정, 삭제하는 비용이 매우 큽니다. 하나의 노드가 변경되면, 그 노드의 오른쪽에 있는 모든 노드의
Closure Table
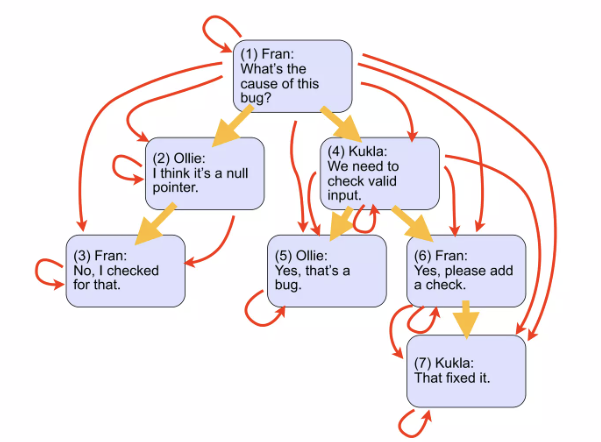
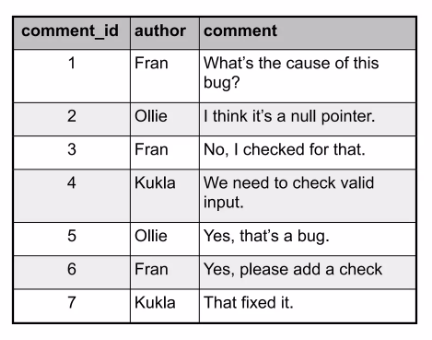
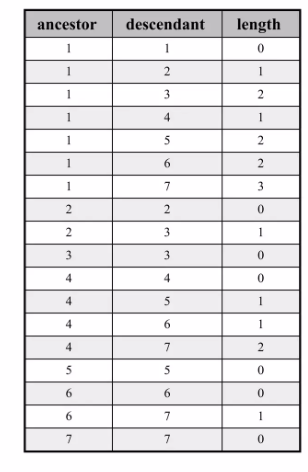
계층 구조의 모든 경로 정보를 별도의 테이블에 저장하는 방식입니다. 이 테이블은 특정 노드에서 다른 노드까지의 모든 경로와 깊이(depth)를 기록합니다.
- 장점:
- 서브트리 조회 성능이 좋습니다. (JOIN 연산만으로 가능)
- 노드를 추가, 삭제할 때 중첩 집합 모델보다 훨씬 간단하고 비용이 적습니다.
- 데이터 무결성을 유지하기 좋습니다.
- 단점:
- 경로 정보를 저장하기 위한 별도의 테이블이 필요하며, 이로 인해 저장 공간이 더 많이 필요합니다.
결론
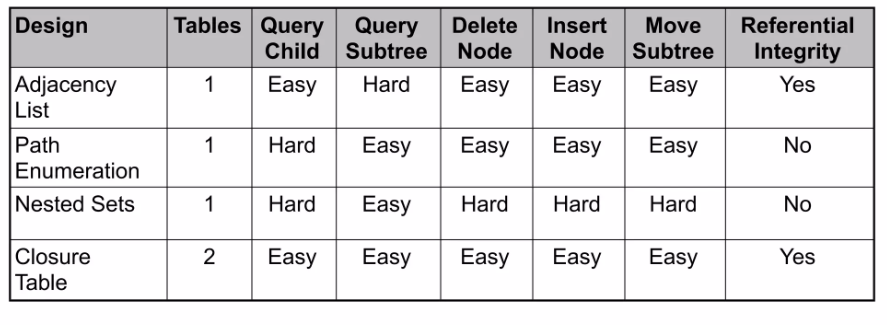
각 모델은 명확한 장단점을 가지고 있으므로, 애플리케이션의 특성에 맞는 방식을 선택하는 것이 중요합니다.
- Adjacency List: 쓰기가 잦고, 전체 트리를 조회하는 일이 거의 없는 경우에 적합합니다.
- Path Enumeration: 경로 정보가 중요하고, 깊이가 깊지 않은 트리에 적합합니다.
- Nested Set: 데이터 변경이 거의 없고, 읽기(특히 서브트리 조회)가 매우 잦은 경우에 적합합니다.
- Closure Table: 읽기와 쓰기 성능의 균형이 필요할 때 좋은 선택이 될 수 있습니다.